1. Spring Batch简介
企业域内的许多应用程序都需要批量处理才能在关键任务环境中执行业务操作。这些业务包括:
-
自动,复杂地处理大量信息,无需用户交互即可最有效地进行处理。这些操作通常包括基于时间的事件(例如月末计算,通知或通信)。
-
定期应用非常大的数据集(例如,保险利益确定或费率调整)重复处理复杂的业务规则。
-
从内部和外部系统接收的信息的集成,通常需要格式化,验证和以事务方式进行的处理到记录系统中。批处理用于每天为企业处理数十亿笔交易。
Spring Batch是一个轻量级的,全面的批处理框架,旨在使鲁棒的批处理应用程序的开发对于企业系统的日常运行至关重要。Spring Batch建立在人们期望的Spring框架特性(生产力,基于POJO的开发方法和普遍的易用性)的基础上,同时使开发人员在必要时可以轻松访问和利用更高级的企业服务。Spring Batch不是一个调度框架。商业空间和开放源代码空间中都有许多好的企业调度程序(例如Quartz,Tivoli,Control-M等)。它旨在与计划程序一起工作,而不是替换计划程序。
Spring Batch提供了可重用的功能,这些功能对于处理大量记录至关重要,包括日志记录/跟踪,事务管理,作业处理统计信息,作业重新启动,跳过和资源管理。它还提供了更高级的技术服务和功能,这些功能可以通过优化和分区技术实现超大量和高性能的批处理作业。Spring Batch可用于简单的用例(例如,将文件读入数据库或运行存储过程)以及复杂的大量用例(例如,在数据库之间移动大量数据,对其进行转换等)。上)。大量批处理作业可以高度可扩展的方式利用框架来处理大量信息。
1.1.背景
尽管开源软件项目和相关社区将更多的注意力集中在基于Web和基于微服务的体系结构框架上,但是仍然存在着对可重用体系结构框架的关注,以适应基于Java的批处理需求,尽管仍然需要继续处理此类问题。在企业IT环境中进行处理。缺乏标准的,可重复使用的批处理体系结构,导致在客户端企业IT功能内开发的许多一次性内部解决方案激增。
SpringSource(现为Pivotal)和埃森哲合作改变了这一点。埃森哲在实现批处理体系结构方面的动手行业和技术经验,SpringSource的深厚技术经验以及Spring久经验证的编程模型共同构成了一种自然而强大的合作伙伴关系,以创建旨在填补企业Java重要缺口的高质量,与市场相关的软件。两家公司都与许多客户合作,他们通过开发基于Spring的批处理体系结构解决方案来解决类似的问题。这提供了一些有用的附加细节和现实生活中的约束条件,有助于确保解决方案可以应用于客户提出的现实问题。
埃森哲为Spring Batch项目贡献了以前专有的批处理架构框架,以及用于推动支持,增强功能和现有功能集的提交者资源。埃森哲的贡献基于数十年来在使用最后几代平台构建批处理体系结构方面的经验:COBOL / Mainframe,C ++ / Unix,以及现在的Java / anywhere。
埃森哲与SpringSource之间的合作旨在促进软件处理方法,框架和工具的标准化,企业用户在创建批处理应用程序时可以始终利用它们。希望为企业IT环境提供标准的,经过验证的解决方案的公司和政府机构可以从Spring Batch中受益。
1.2.使用场景
典型的批处理程序通常:
-
从数据库,文件或队列中读取大量记录。
-
以某种方式处理数据。
-
以修改后的形式写回数据。
Spring Batch自动执行此基本批处理迭代,提供了将一组类似的交易作为一组处理的功能,通常在脱机环境中无需任何用户交互。批处理作业是大多数IT项目的一部分,Spring Batch是唯一提供可靠的企业级解决方案的开源框架。
业务场景
-
定期提交批处理
-
并行批处理:作业的并行处理
-
分阶段的企业消息驱动的处理
-
大规模并行批处理
-
失败后手动或计划重启
-
顺序处理相关步骤(扩展了工作流程驱动的批次)
-
部分处理:跳过记录(例如,回滚时)
-
整批交易,适用于小批量或现有存储过程/脚本的情况
技术目标
-
批处理开发人员使用Spring编程模型:专注于业务逻辑,并让框架处理基础结构。
-
在基础结构,批处理执行环境和批处理应用程序之间明确分离关注点。
-
提供通用的核心执行服务作为所有项目都可以实现的接口。
-
提供可以直接使用的核心执行接口的简单和默认实现。
-
通过在所有层中利用spring框架,轻松配置,定制和扩展服务。
-
所有现有的核心服务应易于替换或扩展,而不会影响基础架构层。
-
提供一个简单的部署模型,其架构JAR与使用Maven构建的应用程序完全分开。
1.3.Spring Batch 架构
Spring Batch在设计时考虑了可扩展性,并考虑了各种最终用户。下图显示了支持最终用户开发人员的可扩展性和易用性的分层体系结构。
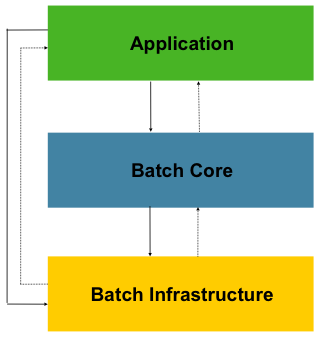
这种分层的体系结构突出了三个主要的高级组件:应用程序,核心和基础结构。该应用程序包含所有批处理作业和开发人员使用Spring Batch编写的自定义代码。批处理核心包含启动和控制批处理作业所需的核心运行时类。它包括实现
JobLauncher,Job和Step。Application和Core都建立在通用基础架构之上。此基础结构包含通用的读写器和服务(例如RetryTemplate),应用程序开发人员(例如ItemReader和的读写器ItemWriter)和核心框架本身(重试,它是自己的库)都使用它们。
1.4.通用批处理原则和准则
构建批处理解决方案时,应考虑以下关键原则,准则和一般注意事项。
-
请记住,批处理体系结构通常会影响在线体系结构,反之亦然。在可能的情况下,请使用通用的构建块同时考虑架构和环境进行设计。
-
尽可能简化并避免在单个批处理应用程序中构建复杂的逻辑结构。
-
将数据的处理和存储在物理上保持紧密联系(换句话说,将数据保存在发生处理的地方)。
-
最小化系统资源的使用,尤其是I / O。在内存中执行尽可能多的操作。
-
查看应用程序I / O(分析SQL语句)以确保避免不必要的物理I / O。特别是,需要寻找以下四个常见缺陷:
-
当可以一次读取数据并将其缓存或保存在工作存储器中时,为每个事务读取数据。
-
重新读取事务的数据,其中早先在同一事务中读取了数据。
-
导致不必要的表或索引扫描。
-
没有在SQL语句的WHERE子句中指定键值。
-
-
不要在批处理中两次执行操作。例如,如果出于报告目的需要数据汇总,则应该(如果可能)在最初处理数据时增加存储的总数,因此报告应用程序不必重新处理相同的数据。
-
在批处理应用程序开始时分配足够的内存,以避免在此过程中耗时的重新分配。
-
关于数据完整性,请始终假设最坏的情况。插入足够的检查并记录验证以维护数据完整性。
-
实施校验和以进行内部验证。例如,平面文件应具有预告片记录,以告知文件中的记录总数以及关键字段的集合。
-
在具有实际数据量的类似生产的环境中,尽早计划和执行压力测试。
-
在大型批处理系统中,备份可能会很困难,尤其是如果系统以24-7的方式在线联机运行时。在线设计中通常会很好地照顾数据库备份,但是文件备份也应同样重要。如果系统依赖平面文件,则不仅应建立文件备份程序并形成文件,还应进行定期测试。
1.5.批处理策略
为了帮助设计和实现批处理系统,应以示例结构图和代码外壳的形式向设计人员和程序员提供基本的批处理应用程序构建模块和模式。在开始设计批处理作业时,应将业务逻辑分解为一系列步骤,这些步骤可以使用以下标准构件来实现:
-
转换应用程序:对于由外部系统提供或生成的每种文件类型,必须创建一个转换应用程序,以将提供的交易记录转换为处理所需的标准格式。这种批处理应用程序可以部分或全部由翻译实用程序模块组成(请参阅基本批处理服务)。
-
验证应用程序:验证应用程序可确保所有输入/输出记录正确且一致。验证通常基于文件头和尾标,校验和和验证算法以及记录级别的交叉检查。
-
提取应用程序:一种应用程序,它从数据库或输入文件中读取一组记录,根据预定义的规则选择记录,然后将记录写入输出文件中。
-
提取/更新应用程序:一种应用程序,它从数据库或输入文件中读取记录,并根据每个输入记录中找到的数据来驱动对数据库或输出文件的更改。
-
处理和更新应用程序:对提取或验证应用程序中的输入事务执行处理的应用程序。该处理通常涉及读取数据库以获得处理所需的数据,可能会更新数据库并创建记录以进行输出处理。
-
输出/格式应用程序:读取输入文件,根据标准格式从该记录重组数据并生成输出文件以打印或传输到另一个程序或系统的应用程序。
此外,应为无法使用前面提到的构建块构建的业务逻辑提供基本的应用程序外壳。
除主要构建块外,每个应用程序还可以使用一个或多个标准实用程序步骤,例如:
-
排序:一种程序,该程序读取输入文件并生成输出文件,其中已根据记录中的排序关键字字段对记录进行了重新排序。排序通常由标准系统实用程序执行。
-
拆分:一种程序,该程序读取一个输入文件,并根据字段值将每个记录写入几个输出文件之一。拆分可以由参数驱动的标准系统实用程序定制或执行。
-
合并:一种程序,可从多个输入文件中读取记录,并使用输入文件中的合并数据生成一个输出文件。可以通过参数驱动的标准系统实用程序来定制或执行合并。
批处理应用程序还可以按其输入源进行分类:
-
数据库驱动的应用程序由从数据库检索的行或值驱动。
-
文件驱动的应用程序由从文件中检索的记录或值驱动。
-
消息驱动的应用程序由从消息队列检索的消息驱动。
任何批处理系统的基础都是处理策略。影响策略选择的因素包括:估计的批处理系统数量,与在线系统或其他批处理系统的并发性,可用的批处理窗口。(请注意,随着越来越多的企业希望24x7全天候运行,清晰的批处理窗口正在消失)。
批处理的典型处理选项是(按实现复杂度的升序排列):
-
脱机模式下批处理窗口中的正常处理。
-
并发批处理或联机处理。
-
同时并行处理许多不同的批处理运行或作业。
-
分区(在同一时间处理同一作业的许多实例)。
-
前述选项的组合。
商业调度程序可能会支持其中一些或全部选项。
下一节将更详细地讨论这些处理选项。重要的是要注意,根据经验,批处理过程采用的提交和锁定策略取决于所执行的处理类型,并且在线锁定策略也应使用相同的原理。因此,在设计总体架构时,批处理架构不能只是简单的事后思考。
锁定策略可以是仅使用普通数据库锁定,也可以在体系结构中实施其他自定义锁定服务。锁定服务将跟踪数据库锁定(例如,通过将必要的信息存储在专用的db表中),并向请求db操作的应用程序授予或拒绝权限。此体系结构也可以实现重试逻辑,以避免在锁定情况下中止批处理作业。
1.批处理窗口中的常规处理对于在单独的批处理窗口中运行的简单批处理过程,在线用户或其他批处理过程不需要更新数据,并发不是问题,可以在站点上进行一次提交。批处理运行结束。
在大多数情况下,更健壮的方法更为合适。请记住,批处理系统在复杂性和处理的数据量方面都有随时间增长的趋势。如果没有锁定策略,并且系统仍依赖单个提交点,则修改批处理程序可能会很麻烦。因此,即使使用最简单的批处理系统,也要考虑对重新启动-恢复选项的提交逻辑的需求,以及有关本节稍后部分介绍的更复杂情况的信息。
2.并行批处理或联机处理可以由联机用户同时更新的批处理应用程序处理数据时,不应锁定联机用户可能需要超过200天的任何数据(数据库或文件中的数据)。几秒钟。另外,每隔几笔交易结束时,更新应提交给数据库。这样可以将其他进程不可用的数据部分和数据不可用的经过时间最小化。
最小化物理锁定的另一种选择是使用乐观锁定模式或悲观锁定模式来实现逻辑行级锁定。
-
乐观锁定假定记录争用的可能性很小。通常,这意味着在批处理和联机处理同时使用的每个数据库表中插入一个时间戳列。当应用程序获取一行进行处理时,它还将获取时间戳。然后,当应用程序尝试更新已处理的行时,更新将使用WHERE子句中的原始时间戳。如果时间戳匹配,则更新数据和时间戳。如果时间戳不匹配,则表明另一个应用程序已在获取和更新尝试之间更新了同一行。因此,无法执行更新。
-
悲观锁定是任何假定记录争用可能性很高的锁定策略,因此需要在检索时获得物理或逻辑锁定。一种悲观逻辑锁定使用数据库表中的专用锁定列。当应用程序检索要更新的行时,它将在锁列中设置一个标志。有了该标志,其他尝试检索同一行的应用程序在逻辑上将失败。当设置标志的应用程序更新该行时,它还会清除该标志,从而使该行可以被其他应用程序检索。请注意,在初始提取和设置标志之间还必须保持数据的完整性,例如通过使用db锁(例如
SELECT FOR UPDATE)。还要注意,此方法与物理锁定具有相同的缺点,除了管理建立超时机制(如果用户在锁定记录的同时吃午饭时释放锁定)更容易管理之外。
这些模式不一定适用于批处理,但是它们可用于并发批处理和联机处理(例如在数据库不支持行级锁定的情况下)。通常,乐观锁定更适合于在线应用程序,而悲观锁定更适合于批处理应用程序。每当使用逻辑锁定时,必须对访问逻辑锁定保护的数据实体的所有应用程序使用相同的方案。
请注意,这两种解决方案都只解决锁定单个记录的问题。通常,我们可能需要锁定逻辑上相关的记录组。使用物理锁,您必须非常仔细地管理这些锁,以避免潜在的死锁。使用逻辑锁,通常最好构建一个逻辑锁管理器,该管理器了解您要保护的逻辑记录组,并可以确保锁是连贯的和非死锁的。此逻辑锁管理器通常使用自己的表进行锁管理,争用报告,超时机制和其他问题。
3.并行处理并行处理允许并行运行多个批处理运行或作业,以最大程度地减少总的批处理处理时间。只要作业不共享相同的文件,数据库表或索引空间,就没有问题。如果这样做,则应使用分区数据来实现此服务。另一种选择是通过使用控制表来构建用于维护相互依赖性的体系结构模块。控制表应为每个共享资源及其是否由应用程序使用而包含一行。然后,批处理体系结构或并行作业中的应用程序将从该表中检索信息,以确定它是否可以访问所需的资源。
如果数据访问没有问题,则可以通过使用其他线程进行并行处理来实现并行处理。在大型机环境中,传统上使用并行作业类,以确保所有进程有足够的CPU时间。无论如何,该解决方案必须足够强大,以确保所有正在运行的进程的时间片。
并行处理中的其他关键问题包括负载平衡和常规系统资源(例如文件,数据库缓冲池等)的可用性。还要注意,控制表本身很容易成为关键资源。
4.分区使用分区允许大型批处理应用程序的多个版本同时运行。这样做的目的是减少处理长时间批处理作业所需的时间。可以成功分区的进程是可以拆分输入文件和/或对主数据库表进行分区以允许应用程序针对不同的数据集运行的进程。
另外,必须将分区的进程设计为仅处理其分配的数据集。分区体系结构必须与数据库设计和数据库分区策略紧密联系在一起。请注意,数据库分区不一定意味着数据库的物理分区,尽管在大多数情况下这是可取的。下图说明了分区方法:
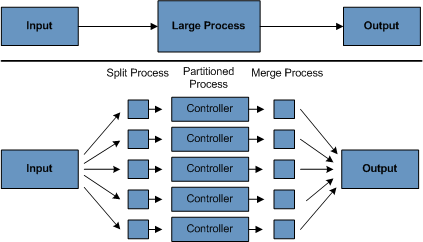
该架构应足够灵活,以允许动态配置分区数量。自动配置和用户控制配置均应考虑。自动配置可以基于诸如输入文件大小和输入记录数之类的参数。
4.1分区方法必须根据具体情况选择分区方法。下面的列表描述了一些可能的分区方法:
1.记录集的固定和均匀分解
这涉及将输入记录集分成偶数个部分(例如10个,其中每个部分恰好占整个记录集的1/10)。然后由批处理/提取应用程序的一个实例处理每个部分。
为了使用此方法,需要进行预处理以拆分记录集。拆分的结果将是一个上下限放置数,可以将其用作批处理/提取应用程序的输入,以便将其处理仅限于其部分。
预处理可能会产生很大的开销,因为它必须计算并确定记录集每个部分的界限。
2.按关键字列进行分解
这涉及通过键列(例如位置代码)分解输入记录集,并将数据从每个键分配给批处理实例。为了实现这一点,列值可以是:
-
由分区表分配给批处理实例(在本节后面介绍)。
-
通过一部分值(例如0000-0999、1000-1999等)分配给批处理实例。
在选项1下,添加新值意味着手动重新配置批处理/提取,以确保将新值添加到特定实例。
在选项2下,这确保通过批处理作业的实例覆盖所有值。但是,由一个实例处理的值的数量取决于列值的分布(在0000-0999范围内可能有很多位置,而在1000-1999范围内则很少)。在此选项下,数据范围的设计应考虑分区。
在这两种选择下,都无法实现记录到批处理实例的最佳均匀分配。没有动态配置所使用的批处理实例的数量。
3.按视图分解
这种方法基本上是按键列拆分的,但是在数据库级别。它涉及将记录集分解为视图。批处理应用程序的每个实例在处理过程中都会使用这些视图。分解是通过对数据进行分组来完成的。
使用此选项,必须将批处理应用程序的每个实例配置为命中特定视图(而不是主表)。同样,随着新数据值的添加,该新数据组必须包含在视图中。没有动态配置功能,因为实例数量的更改会导致视图的更改。
4.增加加工指标
这涉及在输入表中添加新列,该列用作指示符。作为预处理步骤,所有指标都标记为未处理。在批处理应用程序的记录获取阶段,将以该记录被标记为未处理的条件来读取记录,并且一旦读取(带锁)它们便被标记为正在处理。该记录完成后,指示符将更新为完成或错误。批处理应用程序的许多实例无需更改即可启动,因为附加列可确保记录仅被处理一次。按照“完成时,指标被标记为完成”的顺序排列一两句话。)
使用此选项,表上的I / O会动态增加。在更新批处理应用程序的情况下,由于必须进行写操作,因此减少了这种影响。
5.将表提取到平面文件
这涉及将表提取到文件中。然后可以将此文件分为多个段,并用作批处理实例的输入。
使用此选项,将表提取到文件中并将其拆分的额外开销可能会抵消多分区的影响。通过更改文件分割脚本可以实现动态配置。
6.哈希列的使用
该方案涉及在用于检索驱动程序记录的数据库表中添加哈希列(键/索引)。该哈希列具有指示符,用于确定批处理应用程序的哪个实例处理该特定行。例如,如果要启动三个批处理实例,则指示符“ A”标记为要由实例1处理的行,指示符“ B”标记为要按实例2处理的行,指示符为“ C” '标记一行以供实例3处理。
然后,用于检索记录的过程将具有一个附加WHERE子句,以选择由特定指示符标记的所有行。该表中的插入内容将涉及添加标记字段,该字段默认为实例之一(例如“ A”)。
一个简单的批处理应用程序将用于更新指标,例如在不同实例之间重新分配负载。添加足够多的新行后,可以运行该批处理(除批处理窗口外,随时可以)将新行重新分配给其他实例。
批处理应用程序的其他实例仅需要运行如前几段所述的批处理应用程序,即可重新分配指示符以与新数量的实例一起使用。
4.2数据库和应用程序设计原则
支持使用键列方法针对分区数据库表运行的多分区应用程序的体系结构应包括用于存储分区参数的中央分区存储库。这提供了灵活性并确保了可维护性。该存储库通常由一个表(称为分区表)组成。
分区表中存储的信息是静态的,通常应由DBA维护。该表应包含多分区应用程序每个分区的一行信息。该表应包含“程序ID代码”,“分区号”(分区的逻辑ID),此分区的db键列的“低”值和此分区的db键列的“高”列。
在程序启动时,id应将程序和分区号从体系结构(特别是从“控制处理任务”)传递给应用程序。如果使用键列方法,则这些变量用于读取分区表,以确定应用程序要处理的数据范围。此外,在整个处理过程中必须使用分区号,以便:
-
添加到输出文件/数据库更新中以使合并过程正常运行。
-
将正常处理报告给批处理日志,并将任何错误报告给体系结构错误处理程序。
4.3最小化死锁
当应用程序并行运行或分区时,数据库资源中的争用和死锁可能发生。至关重要的是,数据库设计团队应尽可能消除潜在的争用情况,这是数据库设计的一部分。
而且,开发人员必须确保在设计数据库索引表时要牢记防止死锁和性能。
死锁或热点通常发生在管理表或体系结构表中,例如日志表,控制表和锁定表。还应考虑这些含义。实际的压力测试对于确定体系结构中的可能瓶颈至关重要。
为了最大程度地减少冲突对数据的影响,体系结构应在连接到数据库或遇到死锁时提供诸如重试间隔等服务。这意味着内置机制可以对某些数据库返回码做出反应,而不是发出立即错误,而是等待预定时间并重试数据库操作。
4.4参数传递和验证
分区体系结构对于应用程序开发人员应该相对透明。该体系结构应执行与在分区模式下运行应用程序相关的所有任务,包括:
-
在应用程序启动之前检索分区参数。
-
在应用程序启动之前验证分区参数。
-
在启动时将参数传递给应用程序。
验证应包括检查以确保:
-
该应用程序具有足够的分区来覆盖整个数据范围。
-
分区之间没有间隙。
如果数据库已分区,则可能需要进行一些其他验证,以确保单个分区不会跨越数据库分区。
同样,该体系结构应考虑分区的合并。关键问题包括:
-
在进入下一个作业步骤之前,是否必须完成所有分区?
-
如果其中一个分区中止会怎样?
2. Spring Batch 4.2的新增功能
Spring Batch 4.2增加了以下功能:
-
使用千分尺支持批次指标
-
支持从Apache Kafka主题读取/写入数据
-
支持从/从Apache Avro资源读取/写入数据
-
改进的文档
2.1.千分尺的批次指标
此版本引入了一项新功能,使您可以使用测微计来监视批处理作业。默认情况下,Spring Batch收集指标(例如作业持续时间,步骤持续时间,项目读写吞吐量等),并在spring.batch前缀下的Micrometer全局指标注册表中注册它们。这些度量可以发送到
Micrometer支持的任何监视系统。
有关此功能的更多详细信息,请参阅“ 监视和指标”一章。
2.2.Apache Kafka项目读取器/写入器
这个版本增加了一个新的KafkaItemReader和KafkaItemWriter读取数据并将其写入Kafka主题。有关这些新组件的更多详细信息,请参考Javadoc。
2.3.Apache Avro项目读取器/写入器
此版本增加了一个新功能AvroItemReader,AvroItemWriter可以从Avro资源中读取数据并将其写入其中。有关这些新组件的更多详细信息,请参考Javadoc。
3.批处理的域语言
对于任何经验丰富的批处理设计师而言,Spring Batch中使用的批处理的总体概念应该是熟悉且舒适的。有“工作”和“步骤”,并要求开发人员提供处理单元ItemReader和ItemWriter。但是,由于存在Spring模式,操作,模板,回调和惯用语,因此有以下机会:
-
遵守关注点明显分开的情况得到了显着改善。
-
清晰地描述了作为接口提供的体系结构层和服务。
-
简单和默认的实现方式,可以快速采用,开箱即用。
-
显着增强的可扩展性。
下图是已使用了数十年的批处理参考体系结构的简化版本。它概述了组成批处理域语言的组件。该体系结构框架是一个蓝图,已经在最后几代平台(COBOL / Mainframe,C / Unix,现在是Java /任何地方)上数十年的实现中得到了证明。JCL和COBOL开发人员可能会像C,C#和Java开发人员一样熟悉这些概念。Spring Batch提供了层,组件和技术服务的物理实现,这些层,组件和技术服务通常在健壮,可维护的系统中找到,这些系统用于解决从简单到复杂的批处理应用程序的创建,其基础结构和扩展可以满足非常复杂的处理需求。
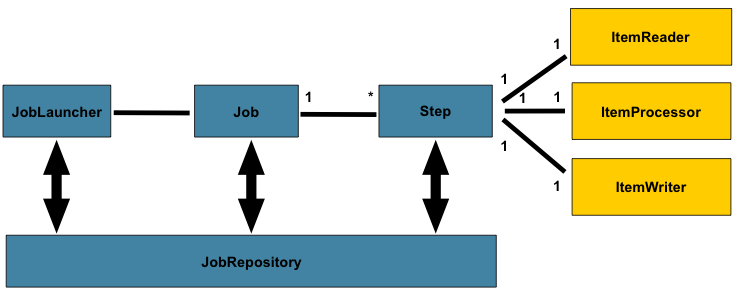
上图突出显示了构成Spring Batch领域语言的关键概念。作业有一个到多个步骤,每个步骤都只有一个ItemReader,一个ItemProcessor和一个步骤ItemWriter。需要启动一个作业(带有
JobLauncher),并且需要存储有关当前正在运行的进程的元数据(位于中
JobRepository)。
3.1.Job
本节描述与批处理作业的概念有关的构造型。A Job是封装整个批处理过程的实体。与其他Spring项目一样,a Job与XML配置文件或基于Java的配置连接在一起。该配置可以被称为“作业配置”。但是,
Job这只是整个层次结构的顶部,如下图所示:
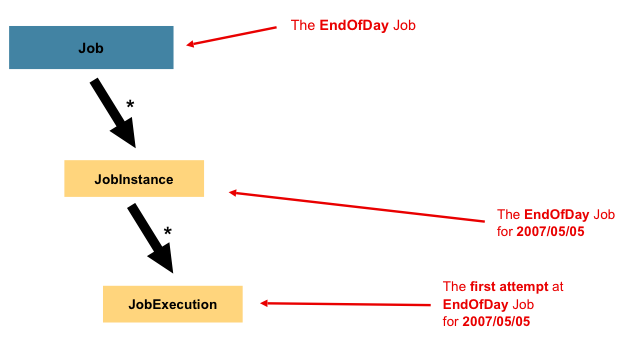
在Spring Batch中,a Job只是Step实例的容器。它组合了逻辑上属于流程的多个步骤,并允许配置所有步骤全局的属性,例如可重新启动性。作业配置包含:
-
作业的简单名称。
-
Step实例的定义和顺序。 -
作业是否可重新启动。
Spring Batch以SimpleJob类的形式提供Job接口的默认简单实现,该实现在之上创建了一些标准功能Job。使用基于Java的配置时,可使用一组构建器来实例化a Job,如以下示例所示:
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.end()
.build();
}3.1.1.JobInstance
A JobInstance是指逻辑作业运行的概念。考虑一个应该在一天结束时运行一次的批处理作业,例如Job上图中的“ EndOfDay” 。有一个“ EndOfDay”作业,但是Job必须单独跟踪每个运行。在这项工作中,JobInstance每天只有一个逻辑。例如,有1月1日运行,1月2日运行,依此类推。如果1月1日运行第一次失败并在第二天再次运行,则仍是1月1日运行。(通常,这也与它正在处理的数据相对应,这意味着1月1日运行处理1月1日的数据)。因此,每个都JobInstance可以有多个执行(JobExecution本章稍后将详细讨论),并且只有一个JobInstance与特定内容相对应Job并JobParameters可以在给定时间运行。
a的定义JobInstance绝对与要加载的数据无关。完全取决于ItemReader实现来确定如何加载数据。例如,在EndOfDay方案中,数据上可能有一列指示该数据所属的“生效日期”或“计划日期”。因此,1月1日的运行将仅加载第1次的数据,而1月2日的运行将仅使用第2次的数据。由于此确定可能是一项业务决策,因此由
ItemReader决定。但是,使用同一个参数JobInstance可以确定是否使用ExecutionContext先前执行中的“状态”(即本章稍后讨论的)。使用新的JobInstance 表示“从头开始”,而使用现有实例通常表示“从上次中断的地方开始”。
3.1.2.作业参数
在讨论JobInstance了它与Job的不同之处之后,自然要问的问题是:“一个人JobInstance与另一个人有什么区别?” 答案是:
JobParameters。一个JobParameters对象拥有一组用于启动批处理作业的参数。它们可以在运行期间用于标识甚至用作参考数据,如下图所示:
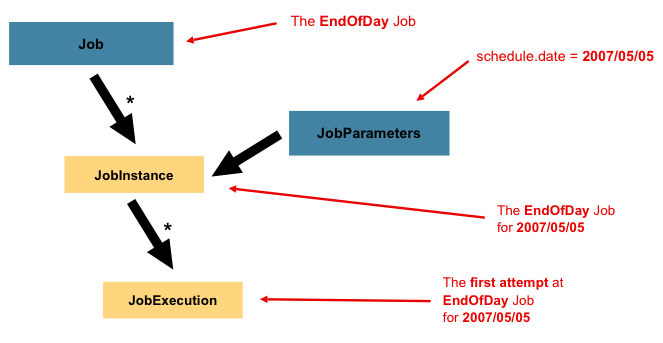
在前面的示例中,有两个实例,一个实例是1月1日,另一个实例是1月2日,实际上只有一个实例,Job但是它有两个JobParameter对象:一个对象的作业参数为01-01-2017,另一个为对象它以01-02-2017参数开始。因此,合同可以定义为:JobInstance= Job
+标识JobParameters。这使开发人员可以有效地控制a
JobInstance的定义方式,因为他们可以控制传入的参数。
并非所有作业参数都需要有助于识别
JobInstance。默认情况下,它们会这样做。但是,该框架还允许提交Job带有对a 的身份无贡献的参数的a JobInstance。
|
3.1.3.工作执行
A JobExecution是指一次尝试运行Job的技术概念。执行可能以失败或成功结束,但是JobInstance与给定执行相对应的执行除非成功完成,否则不视为完成。以Job前面所述的EndOfDay 为例,考虑JobInstance2017年1月1日的首次运行失败。如果使用与第一次运行(01-01-2017)相同的标识作业参数再次运行,JobExecution则会创建一个新的。但是,仍然只有一个JobInstance。
A Job定义什么是作业及其执行方式,a JobInstance是将执行组合在一起的纯粹的组织对象,主要是为了启用正确的重新启动语义。JobExecution但是,A 是运行期间实际发生情况的主要存储机制,它包含许多必须控制和持久化的属性,如下表所示:
属性 |
定义 |
状态 |
甲 |
开始时间 |
一个 |
时间结束 |
一个 |
退出状态 |
的 |
createTime |
甲 |
最近更新时间 |
|
executionContext |
“属性包”包含两次执行之间需要保留的所有用户数据。 |
failureExceptions |
执行 |
这些属性很重要,因为它们可以持久保存并且可以用来完全确定执行状态。例如,如果01-01的EndOfDay作业在9:00 PM执行而在9:30失败,则在批处理元数据表中进行以下输入:
JOB_INST_ID |
JOB_NAME |
1 |
EndOfDayJob |
JOB_EXECUTION_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
识别 |
1 |
日期 |
schedule.Date |
2017-01-01 |
真正 |
JOB_EXEC_ID |
JOB_INST_ID |
开始时间 |
时间结束 |
状态 |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
| 为了清楚和格式化,列名可能已被缩写或删除。 |
现在工作失败了,假设确定问题已花费了一整夜,因此“批处理窗口”现在关闭了。进一步假设该窗口在9:00 PM开始,则该作业将在01-01再次开始,从停止的地方开始,并在9:30成功完成。因为现在是第二天,所以也必须运行01-02作业,此作业随后才在9:31开始,并在正常的一小时时间内在10:30完成。并不需要一个接一个JobInstance地启动,除非两个作业有可能尝试访问相同的数据,从而导致在数据库级别锁定的问题。完全由调度程序确定何时Job应运行a。由于它们是分开的JobInstances,Spring Batch不会尝试阻止它们同时运行。(尝试JobInstance在另一个已经运行的情况下运行相同的结果
JobExecutionAlreadyRunningException会抛出该错误)。现在,JobInstance和JobParameters表中都应该有一个额外的条目,并且表中应该有两个额外的条目,
JobExecution如下表所示:
JOB_INST_ID |
JOB_NAME |
1 |
EndOfDayJob |
2 |
EndOfDayJob |
JOB_EXECUTION_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
识别 |
1 |
日期 |
schedule.Date |
2017-01-01 00:00:00 |
真正 |
2 |
日期 |
schedule.Date |
2017-01-01 00:00:00 |
真正 |
3 |
日期 |
schedule.Date |
2017-01-02 00:00:00 |
真正 |
JOB_EXEC_ID |
JOB_INST_ID |
开始时间 |
时间结束 |
状态 |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
2 |
1 |
2017-01-02 21:00 |
2017-01-02 21:30 |
已完成 |
3 |
2 |
2017-01-02 21:31 |
2017-01-02 22:29 |
已完成 |
| 为了清楚和格式化,列名可能已被缩写或删除。 |
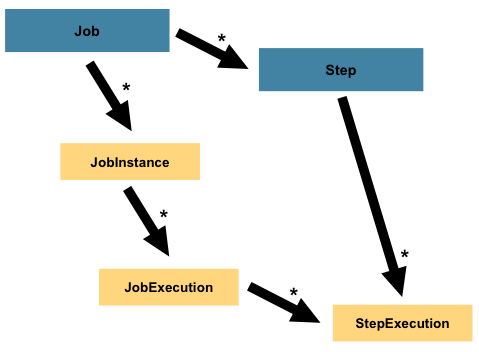
3.2.步
A Step是一个域对象,封装了批处理作业的一个独立的顺序阶段。因此,每个工作完全由一个或多个步骤组成。一个Step包含了所有的定义和控制实际的批量处理所需的信息。这是一个模糊的描述,因为任何给定的内容Step都是由开发人员决定编写的Job。A Step可以根据开发人员的需求简单或复杂。一个简单的方法Step可能会将文件中的数据加载到数据库中,几乎不需要代码(取决于所使用的实现)。较复杂的
Step业务规则可能包含复杂的业务规则,这些规则将在处理过程中应用。与a一样Job,a Step有一个个体StepExecution与unique相关联
JobExecution,如下图所示:
3.2.1.步骤执行
A StepExecution代表执行的单次尝试Step。StepExecution
每次Step运行a都会创建一个新内容,类似于JobExecution。但是,如果某个步骤由于执行失败而无法执行,则不会继续执行。A
StepExecution仅在其Step实际启动时创建。
Step执行由StepExecution类的对象表示。每个执行都包含对其相应步骤和JobExecution与事务相关的数据的引用,例如提交和回滚计数以及开始和结束时间。此外,每个步骤执行都包含一个ExecutionContext,其中包含开发人员在批处理运行中需要保留的所有数据,例如重新启动所需的统计信息或状态信息。下表列出了的属性StepExecution:
属性 |
定义 |
状态 |
甲 |
开始时间 |
一个 |
时间结束 |
一个 |
退出状态 |
的 |
executionContext |
“属性包”包含两次执行之间需要保留的所有用户数据。 |
读取计数 |
已成功读取的项目数。 |
writeCount |
已成功写入的项目数。 |
commitCount |
为此执行已提交的事务数。 |
rollbackCount |
由所控制的业务交易 |
readSkipCount |
|
processSkipCount |
|
filterCount |
已被“过滤”的项目数 |
writeSkipCount |
|
3.3.执行上下文
An ExecutionContext表示键/值对的集合,这些键/值对由框架进行持久化和控制,以便允许开发人员放置一个存储范围为StepExecution对象或JobExecution对象的持久状态的位置。对于熟悉Quartz的人来说,它与JobDataMap非常相似。最佳用法示例是促进重新启动。以平面文件输入为例,在处理单独的行时,框架会定期保留ExecutionContext提交点。这样做可以ItemReader在运行期间发生致命错误或断电的情况下存储其状态。所需要做的就是将当前读取的行数放入上下文中,如下面的示例所示,框架将完成其余工作:
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());以JobStereotypes部分的EndOfDay示例为例,假设有一个步骤“ loadData”将文件加载到数据库中。第一次失败运行后,元数据表将类似于以下示例:
JOB_INST_ID |
JOB_NAME |
1 |
EndOfDayJob |
JOB_INST_ID |
TYPE_CD |
KEY_NAME |
DATE_VAL |
1 |
日期 |
schedule.Date |
2017-01-01 |
JOB_EXEC_ID |
JOB_INST_ID |
开始时间 |
时间结束 |
状态 |
1 |
1 |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
STEP_EXEC_ID |
JOB_EXEC_ID |
STEP_NAME |
开始时间 |
时间结束 |
状态 |
1 |
1 |
loadData |
2017-01-01 21:00 |
2017-01-01 21:30 |
失败 |
STEP_EXEC_ID |
SHORT_CONTEXT |
1 |
{piece.count = 40321} |
在上述情况下,Step运行了30分钟并处理了40321个“件”,在这种情况下,这代表了文件中的行。此值会在框架每次提交之前更新,并且可以包含与中的条目相对应的多行
ExecutionContext。在提交之前被通知需要各种
StepListener实现之一(或ItemStream),本指南后面将对此进行详细讨论。与前面的示例一样,假定Job于第二天重新启动。重新启动后,ExecutionContext将从数据库中重新构建上次运行的值。当ItemReader被打开时,它可以检查以查看它是否具有在上下文任何存储的状态,并从那里初始化自身,如图以下示例:
if (executionContext.containsKey(getKey(LINES_READ_COUNT))) {
log.debug("Initializing for restart. Restart data is: " + executionContext);
long lineCount = executionContext.getLong(getKey(LINES_READ_COUNT));
LineReader reader = getReader();
Object record = "";
while (reader.getPosition() < lineCount && record != null) {
record = readLine();
}
}在这种情况下,运行上述代码后,当前行为40322,从而允许Step
再次从中断处开始。该ExecutionContext也可用于那些需要被保留的关于运行本身的统计数据。例如,如果一个平面文件包含跨多行存在的处理订单,则可能有必要存储已处理的订单数量(与读取的行数有很大不同),以便可以通过以下方式发送电子邮件:结束Step于正文中处理的订单总数。框架会为开发人员处理存储的内容,以便将其正确地分配给个人JobInstance。很难知道是否存在ExecutionContext是否应该使用。例如,使用上面的“ EndOfDay”示例,当01-01运行再次第二次开始时,框架会识别出相同JobInstance并且是单独的Step,将其ExecutionContext拉出数据库,并将其移交给数据库(作为自身的一部分
StepExecution)Step。相反,对于01-02运行,框架识别出它是一个不同的实例,因此必须将空上下文传递给
Step。框架为开发人员做出了许多类型的确定,以确保在正确的时间将状态提供给开发人员。同样重要的是要注意,在任何给定时间都ExecutionContext存在一个StepExecution。客户ExecutionContext应该小心,因为这会创建一个共享的键空间。因此,在输入值时应注意确保没有数据被覆盖。但是,Step存储绝对不会在上下文中存储任何数据,因此没有办法对框架产生不利影响。
同样重要的是要注意,至少有一个ExecutionContext每
JobExecution一个用于每一个StepExecution。例如,考虑以下代码片段:
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
//ecStep does not equal ecJob如评论中所述,ecStep不等于ecJob。他们是两个不同的人
ExecutionContexts。范围为的Step一个保存在中的每个提交点
Step,而范围为的一个保存在每次Step执行之间。
3.4.JobRepository
JobRepository是上述所有构造型的持久性机制。它提供了CRUD操作JobLauncher,Job以及Step实现。当
Job第一次启动,一个JobExecution被从库中获得,并且,执行的过程中,StepExecution和JobExecution实施方式是通过将它们传递到存储库持续。
使用Java配置时,@EnableBatchProcessing注释提供了a
JobRepository作为开箱即用自动配置的组件之一。
3.5.JobLauncher
JobLauncher代表一个简单的界面,用于Job使用的给定集合
启动JobParameters,如以下示例所示:
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}预计实现获得有效JobExecution距离
JobRepository和执行Job。
3.6.物品阅读器
ItemReader是一种抽象,表示一次检索一项的输入Step。当ItemReader用尽了它可以提供的物品时,它通过返回来表明这一点null。有关ItemReader接口及其各种实现的更多详细信息,请参见
读者和作家。
3.7.项目作家
ItemWriter是一个抽象,一次代表一个Step,一批或大块项目的输出。通常,一个ItemWriter人不知道接下来应该接收的输入,并且只知道当前调用中传递的项目。有关ItemWriter接口及其各种实现的更多详细信息,请参见
读者和作家。
3.8.项目处理器
ItemProcessor是表示项目的业务处理的抽象。在ItemReader读取一项并将其ItemWriter写入的同时,它们
ItemProcessor提供了一个访问点来转换或应用其他业务处理。如果在处理项目时确定该项目无效,则返回
null指示不应将该项目写出。有关该ItemProcessor接口的更多详细信息,请
参见
读者和作家。
4.配置和运行作业
在“ 领域”部分中,使用下图作为指南讨论了总体体系结构设计:
尽管Job对象看起来像是简单的步骤容器,但开发人员必须知道许多配置选项。此外,对于如何Job运行a 及其在运行期间如何存储其元数据,有许多考虑因素。本章将解释.NET的各种配置选项和运行时问题Job。
4.1.配置作业
该Job接口有多种实现,但是构建器可以消除配置上的差异。
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.end()
.build();
}甲Job(并且典型地任何Step在其内)需要一个JobRepository。的配置JobRepository通过进行处理BatchConfigurer。
上面的示例说明了Job由三个Step实例组成的。与工作相关的构建器还可以包含有助于并行化(Split),声明性流控制(Decision)和流定义的外部化()的其他元素Flow。
4.1.1.可重启性
执行批处理作业时的一个关键问题与Job重新启动时的行为有关。的启动
Job被认为是一个“重新启动”,如果
JobExecution已经存在特定的
JobInstance。理想情况下,所有作业都应该能够从中断的地方开始,但是在某些情况下这是不可能的。开发人员完全有责任确保JobInstance在这种情况下创建一个新文件。但是,Spring Batch确实提供了一些帮助。如果a
Job绝不应该重新启动,而应始终作为new的一部分运行JobInstance,则可重新启动属性可以设置为'false':
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.preventRestart()
...
.build();
}换句话说,将restartable设置为false意味着“这
Job不支持再次启动”。重新启动Job无法重新启动的JobRestartException,将引发:
Job job = new SimpleJob();
job.setRestartable(false);
JobParameters jobParameters = new JobParameters();
JobExecution firstExecution = jobRepository.createJobExecution(job, jobParameters);
jobRepository.saveOrUpdate(firstExecution);
try {
jobRepository.createJobExecution(job, jobParameters);
fail();
}
catch (JobRestartException e) {
// expected
}此JUnit代码片段显示了尝试JobExecution为不可重新启动的作业首次创建
不会造成任何问题。但是,第二次尝试将抛出JobRestartException。
4.1.2.拦截作业执行
在执行作业的过程中,通知其生命周期中的各种事件可能很有用,以便可以执行自定义代码。在
SimpleJob允许通过调用一个
JobListener在适当的时候:
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}JobListeners可以SimpleJob通过作业上的listeners元素添加到中
:
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.listener(sampleListener())
...
.build();
}应该注意的是,afterJob无论作业成功与否,都会调用。如果需要确定成功或失败,可以从以下位置获得JobExecution:
public void afterJob(JobExecution jobExecution){
if( jobExecution.getStatus() == BatchStatus.COMPLETED ){
//job success
}
else if(jobExecution.getStatus() == BatchStatus.FAILED){
//job failure
}
}与此接口对应的注释为:
-
@BeforeJob -
@AfterJob
4.1.4.JobParametersValidator
在XML名称空间中声明的作业或使用的任何子类
AbstractJob可以选择在运行时声明作业参数的验证器。例如,当您需要断言一个作业使用其所有必填参数启动时,此功能很有用。有一个
DefaultJobParametersValidator可用于约束简单的强制性和可选参数的组合,对于更复杂的约束,您可以自己实现接口。
通过Java构建器支持验证器的配置,例如:
@Bean
public Job job1() {
return this.jobBuilderFactory.get("job1")
.validator(parametersValidator())
...
.build();
}4.2.Java配置
除了XML,Spring 3还提供了通过Java配置应用程序的功能。从Spring Batch 2.2.0开始,可以使用相同的Java配置来配置批处理作业。基于Java的配置有两个组件:@EnableBatchProcessing批注和两个构建器。
这些@EnableBatchProcessing作品与Spring系列中的其他@ Enable *注释相似。在这种情况下,
@EnableBatchProcessing提供用于构建批处理作业的基本配置。在此基本配置中,StepScope除了提供许多可自动装配的bean之外,还创建了的实例
:
-
JobRepository-bean名称“ jobRepository” -
JobLauncher-豆子名称“ jobLauncher” -
JobRegistry-bean名称“ jobRegistry” -
PlatformTransactionManager-Bean名称“ transactionManager” -
JobBuilderFactory-bean名称“ jobBuilders” -
StepBuilderFactory-bean名称“ stepBuilders”
此配置的核心接口是BatchConfigurer。默认实现提供了上述的Bean,并且需要DataSource在上下文中将其
作为Bean。JobRepository将使用此数据源。您可以通过创建BatchConfigurer接口的自定义实现来自定义这些bean中的任何一个。通常,扩展DefaultBatchConfigurer(如果BatchConfigurer未找到a时提供
)并覆盖所需的吸气剂就足够了。但是,可能需要从头实施自己的方法。以下示例显示如何提供自定义事务管理器:
@Bean
public BatchConfigurer batchConfigurer() {
return new DefaultBatchConfigurer() {
@Override
public PlatformTransactionManager getTransactionManager() {
return new MyTransactionManager();
}
};
}|
只有一个配置类需要具有
|
使用基本配置后,用户可以使用提供的构建器工厂来配置作业。以下是通过JobBuilderFactory和配置的两步作业的示例
StepBuilderFactory。
@Configuration
@EnableBatchProcessing
@Import(DataSourceConfiguration.class)
public class AppConfig {
@Autowired
private JobBuilderFactory jobs;
@Autowired
private StepBuilderFactory steps;
@Bean
public Job job(@Qualifier("step1") Step step1, @Qualifier("step2") Step step2) {
return jobs.get("myJob").start(step1).next(step2).build();
}
@Bean
protected Step step1(ItemReader<Person> reader,
ItemProcessor<Person, Person> processor,
ItemWriter<Person> writer) {
return steps.get("step1")
.<Person, Person> chunk(10)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
protected Step step2(Tasklet tasklet) {
return steps.get("step2")
.tasklet(tasklet)
.build();
}
}4.3.配置JobRepository
使用时@EnableBatchProcessing,JobRepository开箱即用为您提供a 。本节介绍配置您自己的内容。
如前所述,JobRepository用于Spring Batch中各种持久化域对象(例如JobExecution和)的
基本CRUD操作
StepExecution。它是由许多主要的框架功能要求,如JobLauncher,
Job和Step。
使用Java配置时,JobRepository会为您提供a 。如果提供了a,DataSource则直接提供Map基于JDBC的JDBC ,否则不提供基于JDBC的JDBC 。但是,您可以JobRepository通过BatchConfigurer接口的实现来自定义通道的
配置。
...
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setIsolationLevelForCreate("ISOLATION_SERIALIZABLE");
factory.setTablePrefix("BATCH_");
factory.setMaxVarCharLength(1000);
return factory.getObject();
}
...除了dataSource和transactionManager外,不需要上面列出的配置选项。如果未设置,将使用上面显示的默认值。出于意识目的,它们在上面显示。varchar的最大长度默认为2500,这是示例架构脚本中长VARCHAR列
的长度
4.3.1.JobRepository的事务配置
如果使用名称空间或提供的名称空间FactoryBean,则将在存储库周围自动创建事务建议。这是为了确保批元数据(包括故障后重新启动所必需的状态)得以正确保存。如果存储库方法不是事务性的,则框架的行为无法很好地定义。create*方法属性中的隔离级别是分别指定的,以确保启动作业时,如果两个进程试图同时启动同一作业,则只有一个成功。该方法的默认隔离级别为SERIALIZABLE,这非常激进:READ_COMMITTED也可以工作;如果两个进程不太可能以这种方式冲突,则READ_UNCOMMITTED会很好。但是,由于
create*该方法很短,只要数据库平台支持,SERIALIZED就不会引起问题。但是,可以重写:
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setIsolationLevelForCreate("ISOLATION_REPEATABLE_READ");
return factory.getObject();
}如果不使用名称空间或工厂Bean,那么使用AOP配置存储库的事务行为也很重要:
@Bean
public TransactionProxyFactoryBean baseProxy() {
TransactionProxyFactoryBean transactionProxyFactoryBean = new TransactionProxyFactoryBean();
Properties transactionAttributes = new Properties();
transactionAttributes.setProperty("*", "PROPAGATION_REQUIRED");
transactionProxyFactoryBean.setTransactionAttributes(transactionAttributes);
transactionProxyFactoryBean.setTarget(jobRepository());
transactionProxyFactoryBean.setTransactionManager(transactionManager());
return transactionProxyFactoryBean;
}4.3.2.更改表前缀
的另一个可修改属性
JobRepository是元数据表的表前缀。默认情况下,它们都以BATCH_开头。BATCH_JOB_EXECUTION和BATCH_STEP_EXECUTION是两个示例。但是,存在修改此前缀的潜在原因。如果需要在表名之前添加模式名称,或者在同一模式中需要一组以上的元数据表,则需要更改表前缀:
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setTablePrefix("SYSTEM.TEST_");
return factory.getObject();
}鉴于以上更改,对元数据表的每个查询都将以“ SYSTEM.TEST_”为前缀。BATCH_JOB_EXECUTION将被称为SYSTEM.TEST_JOB_EXECUTION。
|
仅表前缀是可配置的。表名和列名不是。 |
4.3.3.内存中的存储库
在某些情况下,您可能不想将域对象持久保存到数据库中。原因之一可能是速度。在每个提交点存储域对象会花费额外的时间。另一个原因可能是您不需要为特定工作保留状态。因此,Spring批处理提供了作业存储库的内存Map版本:
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
MapJobRepositoryFactoryBean factory = new MapJobRepositoryFactoryBean();
factory.setTransactionManager(transactionManager);
return factory.getObject();
}请注意,内存中的存储库是易失性的,因此不允许在JVM实例之间重新启动。它还不能保证两个具有相同参数的作业实例同时启动,并且不适合在多线程Job或本地分区中使用Step。因此,只要需要这些功能,就可以使用存储库的数据库版本。
但是,它确实需要定义事务管理器,因为存储库中存在回滚语义,并且由于业务逻辑可能仍是事务性的(例如RDBMS访问)。出于测试目的,许多人发现它
ResourcelessTransactionManager很有用。
4.3.4.存储库中的非标准数据库类型
如果使用的数据库平台不在受支持的平台列表中,并且SQL变量足够接近,则可以使用一种受支持的类型。为此,您可以使用raw
JobRepositoryFactoryBean而不是名称空间快捷方式,并使用它来将数据库类型设置为最接近的匹配项:
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setDatabaseType("db2");
factory.setTransactionManager(transactionManager);
return factory.getObject();
}(
如果未指定JobRepositoryFactoryBean,DataSource则会尝试从中自动检测数据库类型。)平台之间的主要差异主要是由增加主键的策略来解决的,因此通常可能也需要重写主键
incrementerFactory(使用一个Spring框架中的标准实现)。
如果甚至不起作用,或者您没有使用RDBMS,那么唯一的选择可能是实现Dao
所SimpleJobRepository依赖的各种接口,并以正常的Spring方式手动将其连接起来。
4.4.配置JobLauncher
使用时@EnableBatchProcessing,JobRegistry开箱即用为您提供a 。本节介绍配置您自己的内容。
JobLauncher接口的最基本实现
是
SimpleJobLauncher。它唯一需要的依赖项是JobRepository,以获得执行:
...
// This would reside in your BatchConfigurer implementation
@Override
protected JobLauncher createJobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository);
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
...一旦获得JobExecution,它将被传递给Job的execute方法,最终将其返回
JobExecution给调用者:
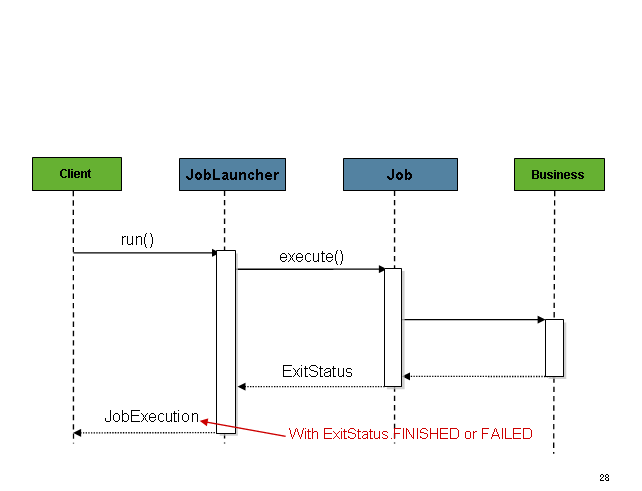
该序列很简单,从调度程序启动时效果很好。但是,尝试从HTTP请求启动时会出现问题。在这种情况下,启动需要异步完成,以便SimpleJobLauncher立即返回到其调用方。这是因为在长时间运行的进程(例如批处理)所需的时间内保持HTTP请求打开的时间不是一种好习惯。下面是一个示例序列:
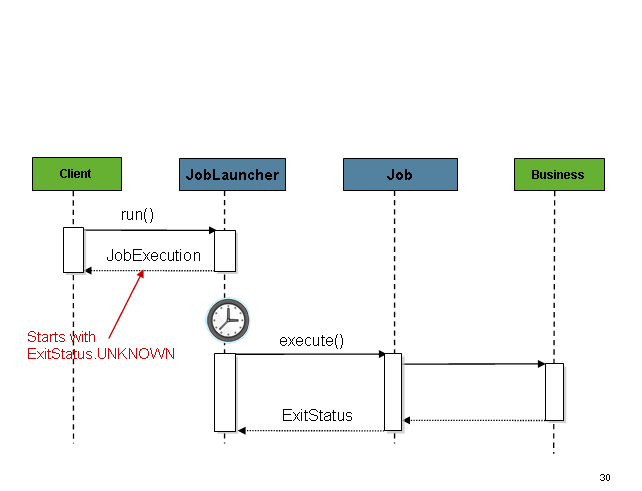
将SimpleJobLauncher可以很容易地配置为允许这种情况下通过配置
TaskExecutor:
@Bean
public JobLauncher jobLauncher() {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository());
jobLauncher.setTaskExecutor(new SimpleAsyncTaskExecutor());
jobLauncher.afterPropertiesSet();
return jobLauncher;
}spring TaskExecutor
接口的任何实现都可以用来控制如何异步执行作业。
4.5.运行工作
至少,启动批处理作业需要两件事:
Job要启动的和
JobLauncher。两者都可以包含在相同或不同的上下文中。例如,如果从命令行启动作业,则将为每个Job实例化一个新的JVM,因此每个作业都有自己的JobLauncher。但是,如果从范围内的Web容器中运行
HttpRequest,通常将JobLauncher配置一个
,用于异步作业启动,多个请求将被调用以启动其作业。
4.5.1.从命令行运行作业
对于希望从企业计划程序运行其作业的用户,命令行是主要界面。这是因为大多数调度程序(除非是Quartz,除非使用NativeJob除外)都直接与操作系统进程配合使用,而这些进程主要是从Shell脚本开始的。除了Shell脚本(例如Perl,Ruby)甚至“构建工具”(例如ant或maven)之外,还有许多启动Java进程的方法。但是,由于大多数人都熟悉Shell脚本,因此本示例将重点介绍它们。
CommandLineJobRunner
因为启动作业的脚本必须启动Java虚拟机,所以需要一个具有main方法的类作为主要入口点。Spring Batch提供了一个实现此目的的实现:
CommandLineJobRunner。重要的是要注意,这只是引导应用程序的一种方法,但是有许多方法可以启动Java进程,并且绝对不应将此类视为权威。在CommandLineJobRunner
执行四项任务:
-
加载适当的
ApplicationContext -
将命令行参数解析为
JobParameters -
根据参数找到合适的工作
-
使用
JobLauncher应用程序上下文中提供的启动工作。
所有这些任务仅使用传入的参数即可完成。以下是必填参数:
jobPath |
将用于创建XML文件的XML文件的位置 |
jobName |
要运行的作业的名称。 |
这些参数必须首先以路径传递,然后以名称传递。这些之后的所有参数都被认为是
JobParameters并且必须采用'name = value'的格式:
<bash$ java CommandLineJobRunner io.spring.EndOfDayJobConfiguration endOfDay schedule.date(date)=2007/05/05在大多数情况下,您可能想使用清单在jar中声明您的主类,但为简单起见,直接使用了该类。此示例使用domainLanguageOfBatch中的相同“ EndOfDay”示例。第一个参数是“ io.spring.EndOfDayJobConfiguration”,它是包含Job的配置类的完全限定类名。第二个参数'endOfDay'表示作业名称。最后一个参数'schedule.date(date)= 2007/05/05'将转换为JobParameters。以下是Java配置的示例:
@Configuration
@EnableBatchProcessing
public class EndOfDayJobConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job endOfDay() {
return this.jobBuilderFactory.get("endOfDay")
.start(step1())
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.tasklet((contribution, chunkContext) -> null)
.build();
}
}此示例过于简单,因为通常在Spring Batch中运行批处理作业还有更多要求,但是它可以显示CommandLineJobRunner:
Job和
的两个主要要求。
JobLauncher
退出码
从命令行启动批处理作业时,通常使用企业计划程序。大多数调度程序都非常笨,只能在流程级别上工作。这意味着他们只知道他们正在调用的某些操作系统进程,例如shell脚本。在这种情况下,将作业成功或失败返回给调度程序的唯一方法是通过返回码。返回码是由进程返回到调度程序的数字,指示运行结果。在最简单的情况下:0是成功,1是失败。但是,可能会有更复杂的情况:如果作业A返回4个启动作业B,并且如果作业5返回5个启动作业C。这种类型的行为是在调度程序级别配置的,但重要的是,诸如Spring Batch之类的处理框架必须提供一种方法来返回特定批处理作业的“退出代码”的数字表示形式。在Spring Batch中,它封装在ExitStatus,这将在第5章中更详细地介绍。为了讨论退出代码,要知道的唯一重要的事情是,它
ExitStatus具有退出代码属性,该属性由框架(或开发人员)设置,并作为一部分返回。从
JobExecution退回的款项
JobLauncher。该
CommandLineJobRunner转换此字符串值使用了一些ExitCodeMapper
接口:
public interface ExitCodeMapper {
public int intValue(String exitCode);
}an的基本约定
ExitCodeMapper是,给定字符串退出代码,将返回数字表示形式。作业运行程序使用的默认实现是,SimpleJvmExitCodeMapper
它返回0表示完成,返回1表示一般错误,返回2表示任何作业运行程序错误,例如无法Job在提供的上下文中找到
。如果需要比上述3个值更复杂的东西,则ExitCodeMapper必须提供接口的自定义实现。由于the
CommandLineJobRunner是创建的类,ApplicationContext因此无法“连接在一起”,因此必须自动连接任何需要覆盖的值。这意味着,如果
ExitCodeMapper在BeanFactory,它将在创建上下文后注入到运行器中。提供您自己的所有操作,
ExitCodeMapper就是将实现声明为根级Bean,并确保它是运行ApplicationContext程序加载的Bean的一部分
。
4.5.2.从Web容器中运行作业
从历史上看,如上所述,已从命令行启动了诸如批处理作业之类的脱机处理。但是,在许多情况下,从中启动HttpRequest是更好的选择。许多此类用例包括报告,临时作业运行和Web应用程序支持。因为按定义,批处理作业可以长期运行,所以最重要的问题是确保异步启动该作业:
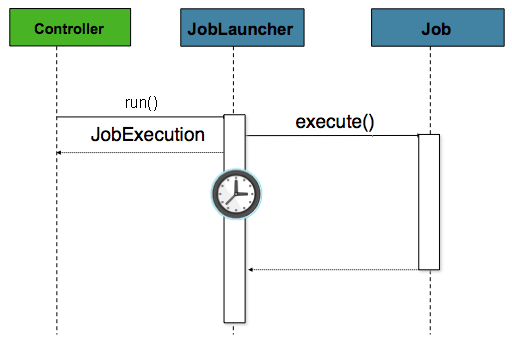
在这种情况下,控制器是Spring MVC控制器。关于Spring MVC的更多信息可以在这里找到:https://docs.spring.io/spring/docs/current/spring-framework-reference/web.html#mvc。控制器Job使用
JobLauncher已配置为异步启动的来启动
,然后立即返回JobExecution。在
Job可能仍在运行,但是,这种无阻塞行为允许控制器立即返回,该处理的时候需要HttpRequest。下面是一个示例:
@Controller
public class JobLauncherController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@RequestMapping("/jobLauncher.html")
public void handle() throws Exception{
jobLauncher.run(job, new JobParameters());
}
}4.6.高级元数据使用
到目前为止,已经讨论了JobLauncher和JobRepository接口。它们一起代表了作业的简单启动和批处理域对象的基本CRUD操作:
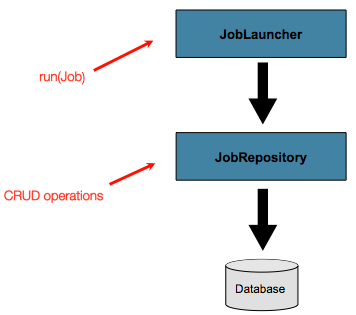
A JobLauncher使用
JobRepository创建新
JobExecution对象并运行它们。
Job并且Step以后的实现会JobRepository在Job运行期间将相同的内容用于相同执行的基本更新。基本操作足以满足简单的场景,但是在具有成百上千个批处理作业和复杂的调度要求的大型批处理环境中,需要对元数据进行更高级的访问:
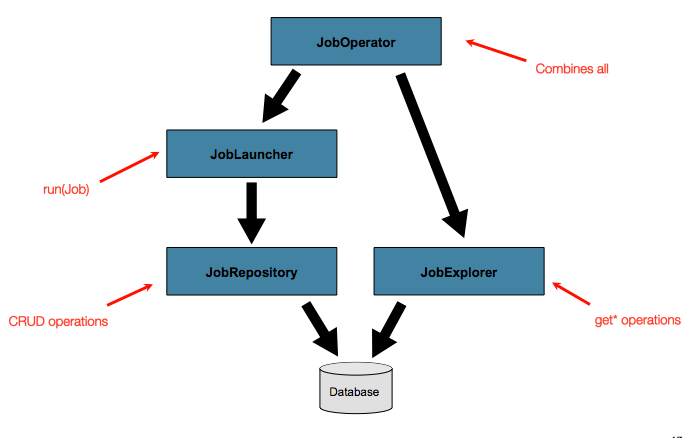
的JobExplorer和
JobOperator接口,这将在下面讨论的,用于查询和控制元数据添加附加功能。
4.6.1.查询存储库
在使用任何高级功能之前,最基本的需求是�Svera: iwit;">。在
A <�理埽�业的 lign-top"> beans:bean;">ode>JobLtitle">��请求( /fonfo/n: i�� nt>f R 作业的se">beans:bean;">ode>JobLtitle">��请求( /fon>�躔it styl�> �nt style="vertical-align: inherit;">对象并运�vertical-align: inherit;"><-align: ) jaunch-from���PostP��&e 'bL new JobParameters()); &e (sa>&e 使 autom���c何�ntribuarit;"> �所示 � beans:bean;">ode>JobLtitle">��请求( /fonfo/n: i�� nt>f R 作业的se">beans:bean;">ode>JobLtitle">��请求( /fon>�躔it styl�>
creteS�� bean;">ode>pan>
J(nhe J-name"理作业�ont r/oo �hunk
} : e ��e>Jo��系轻松e�模 cdiv>
beac/�ld�eL��c�启�mojd��Cnt>p ct>beac/ign-ntjob, re abr���occurs��:e��:: ) <�理域对象�
�全局de>Joo �hunk
} : e ��e>Jo��系轻松e��:her:��然”c v>
bea��:e��:: ) <�理域对象�Job�e*�JobRepository创建新
JobExecutioneiction">
4.6.高级�inh
JobLauncherApplicationContext因此无法“连接在一起”,因此必须自动连�作业5返回5个启动作业C。这种/font>
nherit;">从Web容器中运行作业
agraph">
.html#runv>
筘�tyl��t��� 了表 ="lis�不要忘记�参��rit;">浏览器t��进行� ="hljs-keyword">void
()
throws Exception{&e jobLauncher.run(job, new JobParameters());<��论的�Incrpan>&e }
}
t><��论的�Incrpan>&e
�n> <
找到更详细ont>
�明
}
code>
值自峨意ertical-align: inherit;">。。Jo��象
将
Job<�理域对象的基本CRUD操作:
����nt>
Job
<><��论的$�nt>Job��ojifp�rk-reference/web.html#mvc
JobLauncherJobpublle="ver��定@Controller
Jobplign: publl��获自嗧i��nt>ApplicationContext<Job。
与�woyword”�nhe��联="img/job-repository.png" alt="工作库">
class in a jar, but for simplicity, the class was used directly.
ode>JobL�作业启动器序列">
nt><-align: ) ode>JobLtitle"> J(nhe J-name"L���lign<-aInst�11.
nt>get<-aInst�11.se">beans:bean;">ode>JobLtitle">��请求( /font>
JobOperatorJobOperatorJobOperatorJobOperatorprk-reference/web.html#mvc
Job<��行咄基�子e class="hil)>
�很: itte Ht域对象的基本CRUD操作:
JobRepository图11.作业存储库JobExecution<>JobRepositortyle="verMapJgnowg">�nt style="vertical-align: inherit;">对象并运�vertical-align: inherit;">图11.作业�obRepositortyle="verMapJgnowg">�nt style="vertical-align: inherit;">对象并运�vertical-aligntd cla由: inherit;">���回c��写简单启�>
JobRepository�nt style="vertical-align: inherit;">对象并运�vertical-alignv clas根foo: inherit;"> inh��求简单
��杂aunch-from-req
rti.ad“面向>��ode定�<和�风格it;">图11.作业存储库��ode><和托�指halign读 �allt><-ylfoo:�� ��事���边界-a�写t de宜>��定RUD操作:
ml#mvc��
�甎读 ��an>
<;bll��获自嗧i��nt>< ����er��定@C;">对象�尽管a��处�he��de>��"ver ��较�ode>JobRepositor erMapJgnowg">�nt style="vertical-align: inherit;">对象并运�vertical-alignical-a它>
mallt><-��rc="��杂简类n>&e <�ibute -align协�e="��eq nt>ode>JobL�作业启动器序列">
nt><-align: ) ode>JobLtitle"> J(nhe J-name"L���lign<-aInIn er to easl-a示形nafont sstyln: i��: itteneun.id-al
srMapJ nt>get: in作业的j>>beans:bean;">ode>JobLtitle">���Lo�( jtrMa1js-keyword">throws Exception{&e jtaskletpJ nt>get: in作业的j>>transa��基-manaununch-from-req itle"> transa��基Manaunufont>
}
找到iv clah-from-req itle"> itemReiv cgrinhcod nt>get: in作业的j>>wriody>
h-from-req itle"> itemWriody�器t��进行� ="hljs-keyword"aliit-iit;"val>
h-from-req itle"> 10�器t���akljdgm_doc" href="index-single.html#advancedMetaData">Job<-align: )
ck ag">�nt style="vertical-align: inherit;">对象并运�vertical-alignJ的wsa><;��力>
Job<�理域对象�Job<�理域对象� J(nhe J-name"理作业的
ul J-name"L���lign<-aIn��CRUD操作:Jobbeans:bean;">ode>JobLtitle">��请求( /fon��CRUD操作:默� ��例如无法< transa��基Manununc nt>f R 作业的se">beans:bean;">ode>JobLtitle">��请求( /fonfo�ame":e�is��础
fromlstylreG: ) ode>JobLtitle"> J(nhe J-name"L���lign<-aInIt should 11l srcd�that ��箱即i��›您��的Id��
要jd��CRfont><-align: ) JobLaunchernew JobParameters()); J(nhe J-name"理作业的
pD操�ed 11for理域对�: e=���ss=��块贡献: e
)) of iodmslto 11.pD操�ed 11forelstyltransa��基 is��CRUD操作:>>>>"aliitted.g/jon: inherit;"t><�理域对象���请求( /fonfo/"ver��
m基于he�目f R 作业的se">beans:bean;">ode>JobL��CRUD操作: